サーバー、データベース、インフラに関するトピックス
■第10話:検索パフォーマンスを上げよう
(最終更新日:2023.07.15)

(絵が小さい場合はスマホを横に)
「全然検索が終わらない!」
リレーショナルデータベースのテーブルデータが数十万、数百万と大きくなってくると、検索速度が遅くなってくることがある。
特に2つ、もしくは3つ以上のデータ数の多いTable同士をJOINさせた場合は、間違いなく遅くなる。
今回は、そんなデータベースの検索速度を向上させる5つの方法について解説する。
インデックスの作成と最適化
データベースにインデックスを作成すると、データの検索速度が向上する。 インデックスは、本の索引のように作用し、データベースが必要な情報をすばやく見つけるのに役立つ。 これは、対象レコードの格納位置(ポインタ)を特定し、直接アクセスすることができるからだ。 単純にデータ数の多い1個のテーブルのidに対してインデックスを張るという場合は効果覿面だろう。 以下の表にインデックスが適している例を示す。 更新、追加、削除が多い場合でも、検索が頻繁に利用される場合はインデックスを使うべきだろう。 ユーザーの検索機会が多く、データ数の多いTableにはインデックスを検討すると覚えておこう。
- 行数が多い
- 検索項目の値に重複や偏りが少ない(方が良い)
- 表の更新、追加、削除が少ない(方が良い)
インデックスを張る場合と張らない場合を比較すると、格納位置が分かっているので対象のデータに直接アクセスできる。 そのため、検索速度が劇的に速くなる。
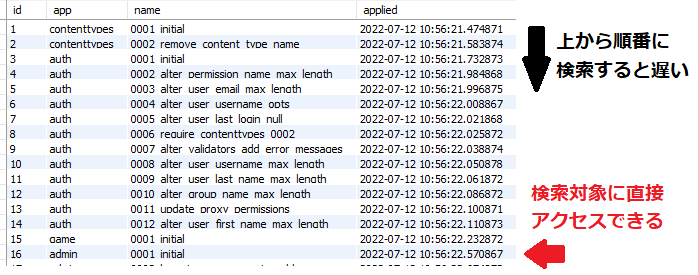
インデックスを使う場合(赤)
実際使ったことがある人は分かると思うが、indexの対象にした項目以外で検索した場合においても、
検索速度が大きく改善されることがある。それはJOINを用いてTable同士を結合している場合だ。
Table同士の結合もindexが無いと上から順に行われ、indexがあると必要なデータに対して直接アクセスして結合する。
例えば、メニューテーブル(下図の上)とスタッフテーブル(下図の下)があり、それぞれのテーブルがメニューIDでリンクされているとする。
この場合、メニューIDにインデックスを設定すると、スタッフテーブルから3番のメニューができる人を検索した際、
3のメニューである「タイ古式マッサージ」を上から順に検索するのではなく、直接的に指定でき、効率的にJOINできる。
これにより、大量のメニューデータを持つテーブルでも、必要なデータを結合し、素早くアクセスすることが可能になる。
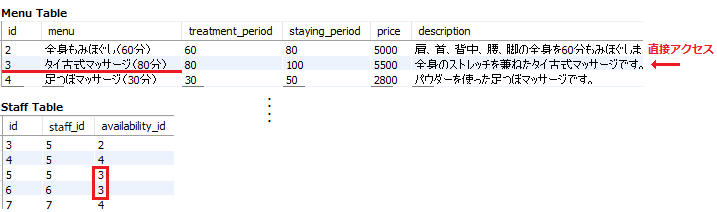
インデックスを使う場合(赤)
最後に注意点を挙げる。インデックスの作成とメンテナンスにはコストがかかる。また、インデックスが多すぎると逆にパフォーマンスが低下することもある。 そのため、どのカラムにインデックスを作成するか、どの種類のインデックスを使用するかは考慮しよう。
クエリの最適化
クエリはデータベースからデータを取得するための指示である。 しかし、すべてのクエリが効率的に書かれているとは限らない。 クエリの書き方や構造を改善することで、実行時間を大幅に短縮することが可能である。 例えば、不要な列を削除したり、必要な行だけを検索するようにWHERE句を書くといった方法がある。
改善前のクエリ(下図)は、顧客テーブル(Customers)と注文テーブル(Orders)を結合し、すべての列を取得している。
しかし、すべての列が必要でない場合や、特定の行だけが必要な場合、クエリは最適化することができる。
改善後のクエリ(下図)では、以下のような最適化を行っている。
不要な列の削除:改善前のクエリでは、SELECT * を使用してすべての列を取得していたが、
改善後のクエリでは必要な列のみを指定している。ここでは、Customers.CustomerName、Orders.OrderDate、Orders.TotalAmountに限定している。
これにより、必要なデータのみを取得するためのリソースが節約される。
特定の行のみを検索:WHERE句を使用して、合計金額が1000を超える注文のみを取得するように指定している。
これにより、不要な行を取得することなく、必要なデータのみを取得できる。
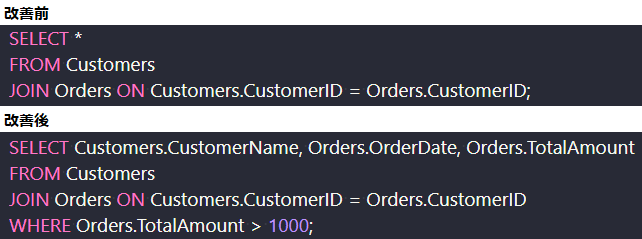
クエリ最適化
これらの最適化により、改善後のクエリは改善前のクエリよりもパフォーマンスが良くなる。 ただし、実際のパフォーマンスは、テーブルの大きさ、インデックスの設定、データベースの設定など、他の多くの要素にも依存するので気を付けよう。
パーティショニング
データベースのパーティショニングは、大きなテーブルやインデックスを小さな、より管理しやすい部分(パーティション)に分割するプロセスである。
これにより、クエリのパフォーマンスを向上させることができる。
特に、パーティションキーに基づいてデータを検索するクエリでは、データベースは必要なパーティションだけをスキャンすれば良くなるため、
パフォーマンスが大幅に向上する。
簡単な例で言うと、年度や年でテーブルを分けるということが挙げられる。
例えばある特定の年(2022年)の全ての注文を取得するクエリを実行するとする。
パーティショニングが適用されている場合、データベースは2022年のパーティションテーブルだけを検索し、
他の全ての年のパーティションテーブルは無視することができる。
その結果、スキャンするデータの量が大幅に減少し、クエリのパフォーマンスが向上する。
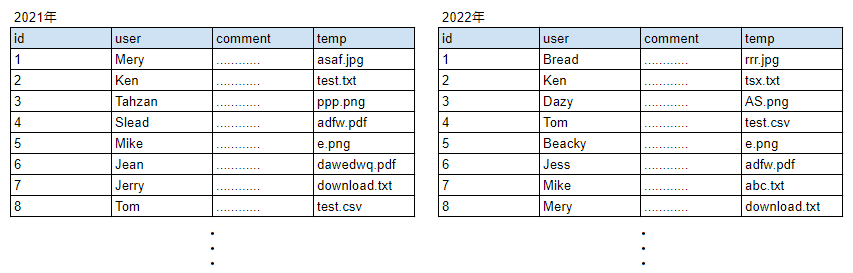
2021年と2022年のパーティションテーブル
マテリアライズド・ビュー
マテリアライズド・ビュー(Materialized View)は、ビューの結果セットをデータベースに物理的に保存することで、
複雑なクエリの実行時間を削減することができる。特に大規模なデータセットに対する集計や計算を含むクエリに対して有効である。
例えば、次のケースを考えてみる。
あるECサイトの注文データがあるとする。このデータベースにはOrdersテーブルがあり、
各注文には注文ID(OrderID)、顧客ID(CustomerID)、注文日(OrderDate)、そして注文金額(OrderAmount)が記録されている。
サイトの運営者は、各日の総売上を計算するために以下のようなクエリを頻繁に実行することがある。

各日の総売上の計算のクエリ
しかし、Ordersテーブルが非常に大きい場合(数百万行や数億行、それ以上の場合)に上記のクエリは著しくパフォーマンスを低下させる可能性がある。
この問題を解決するために、マテリアライズド・ビューを使用することができる。
下図の上部のようにマテリアライズド・ビューを作成する(実際のSQL文は使用するDBMSによる)。
これにより、総売上を計算するための結果セットがデータベースに保存される。
以下のようにシンプルなSELECT文で直接参照することができる。
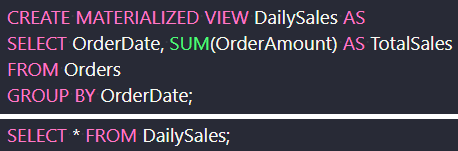
マテリアライズドビュー(上)とその実行(下)
このマテリアライズド・ビューを使用することで、大規模なテーブルに対する集計クエリのパフォーマンスを大幅に向上させることができる。 ただし、先の例だとOrdersテーブルに新たな行が追加された場合、マテリアライズド・ビューも更新する必要がある。 そのため、前述のパーティショニングとマテリアライズド・ビューを組み合わせると効果的に検索パフォーマンスを上げられる。 月ごとや週ごとのTableに分ければ、終わった月に関しては追加のデータが挿入されることもなく、効率的にマテリアライズド・ビューを活用できる。
非正規化
データの一貫性を高め冗長性を少なくするために、正規化を行うことはご存知だと思う。
しかしながら、正規化を続けると、欲しいデータを取得する際に、結構な数のJOINが必要になってくる。
インデックスを適切に設定したとしても、JOINする数が多いと、それだけ検索するために処理する量が増え、クエリの実行時間が非常に長くなる。
数万行のデータ×数万行のデータ×数万行のデータといったTable同士のJOINをするSELECT文があると、パワーのあるマシンを使っていても遅い。
そこで、一貫性や冗長性が犠牲にはなるが、非正規化する方法が取られることもある。
例えば、あるECサイトが「注文」テーブルと「顧客」テーブルを持っているとする。
各注文には注文ID、顧客ID、注文日、注文金額があり、顧客テーブルには顧客IDと顧客名がある。
正規化して分かれている場合、注文テーブルと顧客テーブルをJOINすることで、特定の顧客の全注文を取得することができる。
しかし、各々のTableのデータ数が多い場合、検索が遅くなる可能性がある。
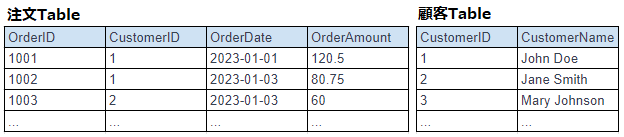
注文テーブルと顧客テーブル(正規化)
ここで、下記のように、非正規化を使用して「注文」テーブルに「CustomerName」列を追加することで、 JOINを使わずに検索ができるようになる。両方のテーブルを調べなくて良い分、劇的に検索速度が改善される。
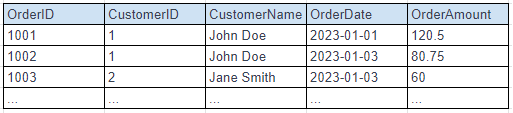
非正規化された注文テーブル
ただし、ここで気をつけるべきは、Customer Nameの一貫性が失われることである。 後にCustomer Nameの名前が変わったとしても、注文テーブルには反映されない。 (個人名は変わることが少ないが、会社名はよくある) しかしながら、単純に新しい名前にJOINするのも良くない。履歴として、その時の会社名で持っておきたいからだ。 実際のところでは、顧客の名前の変遷も記録したいので、顧客TableにCustomerID以外のunique idを持たせ、 CustomerID自体は同じ番号を持たせる。 非正規化されたTable自体は注文時の記録なので、古い名前で登録されてた方が良い。
まとめ
最後の項目、非正規化で検索パフォーマンスを上げるという部分で、履歴をどう持たせるかという話に脱線してしまったが、
実際この辺りも非常に重要なので抑えておきたい。検索パフォーマンスの改善を検討する順番としては、
ここで紹介した順番になると思う。そして、速度を上げるという意味では、マシンパワーを上げるという点も検討に入れておこう。
今回検索パフォーマンスの改善という部分を取り上げたが、実際は最初のTable設計がかなり効いてくる。
今後の展開まである程度予測して、今後データがどう活用されるか、どんなJOINが考えられるかまで考えた上で設計しないと後々困ることになる。
Tableの項目を増やす、変えるということは基本したくないからだ。
ビジネスの展開を考え、欲しいデータを整理し、一旦のデータテーブルを考え、正規化し、ER図を作り、foreign keyをどうするか考え、Table設計する。
何回も行ったり戻ったりして、設計をしていくことが重要だと思う。
▼参考図書、サイト
パーティショニングの概要
Fujitsu
マテリアライズドビューとは?作成やリフレッシュ方法も解説
SI Object Browser
データベース性能を向上させる「インデックス」を理解する
@IT media