JavaScriptのきほんを学ぼう
■第22話:非破壊的な配列操作
(最終更新日:2023.05.13)

(絵が小さい場合はスマホを横に)
「非破壊的な操作で保守性を保つ」
非破壊的な配列操作は、元の配列を変更せずに新しい配列を生成する操作のことである。
この操作は関数型プログラミングの原則に従っている。JavaScriptに用意されている関数を用いることで、
コピー、結合、フィルタリング、マッピング、スライシング、ソーティングといった操作が可能である。
非破壊的な操作は不要な副作用を回避し、予期しないデータ変更を防ぐことができる。
これにより、データの状態管理が容易になり、バグの発生を抑えることができる。
また、非破壊的な操作はコードの可読性や保守性が向上し、複数の開発者が共同で作業する際にも役立つ。
1. 非破壊的操作とは
非破壊的操作とは、元の配列や連想配列に変更を加えずに、新しい配列や連想配列を生成する操作を指す。 この操作は、元のデータの状態を保持しながら、新しいデータ構造に変更を加えることができる。 これにより、不要な副作用を回避し、コードの可読性や保守性が向上する。下記に非破壊操作の例を示す。
まずは配列のコピーである。これまでも説明してきたスプレッド構文を用いた方法である。 スプレッド演算子や Array.prototype.slice() を使用して、元の配列を変更せずに新しい配列を作成できる。

spread演算子を用いた非破壊的なコピー
次に配列の結合である。 Array.prototype.concat() を使用して、元の配列を変更せずに新しい配列に結合できる。 結合したものは[1,2,3,4,5,6]となる。 こちらも、以前と説明した通りの使い方で、非破壊的な操作である。

concatメソッドを用いた非破壊的な結合
次はフィルタリングである。 Array.prototype.filter() を使用して、元の配列を変更せずに特定の条件に合致する要素だけを含む新しい配列を作成する。 下記の場合だと2で割り切れる[2,4]が新しい配列になる。

非破壊的な配列のフィルタリング
最後にマップである。 Array.prototype.map() を使用して、元の配列を変更せずに各要素に関数を適用した新しい配列を作成する。 下記では2倍にする関数を使用しているので、[2,4,6,8,10]が新しい配列になる。
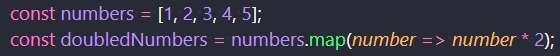
非破壊的な配列のマッピング
2. 配列のスライシング(一部取得)
ここでは、JavaScriptにおけるsliceメソッドを使った配列操作について説明する。 sliceメソッドは、配列の一部を取り出すのに非常に便利な機能である。 下記にその使用例を示す。 sliceメソッドを使用して配列の一部を取り出している。 この例では、インデックス1(banana)からインデックス3(date)の直前までの要素を取り出した。

sliceメソッドによる要素の一部取得
ここで重要なのは元の配列(fruits)はそのままに、slicedFruitsが取り出せることである。 sliceメソッドは非破壊的な操作である。
3. 配列の並び替え(ソーティング)
JavaScriptでは、配列の並び替えを行うためにsortメソッドを使用する。 sortメソッドは、配列の要素を適切な位置に並べ替え、その配列を返す。 デフォルトでは、要素は文字列として変換され、そのUnicodeの文字列順にソートされる。
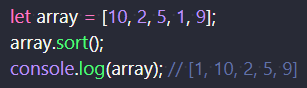
sortメソッドによる文字列の並び変え
上記のコードでは、数値が文字列に変換されてからソートされるため、期待通りの結果にならない。 数値の配列を数値としてソートするには、sortメソッドに比較関数を取り入れる。 すると、数字の小さい順に並べることができる。
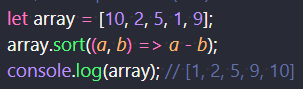
sortメソッドによる数値の並び変え
ここで本題だが、sortメソッドを始め、破壊的なメソッドを用いると、元の配列を変えてしまうことになる。 非破壊的に配列をソートしたい場合は、先にslice()メソッドなどで配列をコピーしてからソートするというテクニックが有効である。 下記では、sliceメソッドを1つ挟むことによって、コピーしたものに対して並び替えを行っている。 (ちなみに、スプレッド演算子で配列をコピーする方法でも良い)
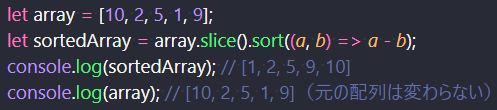
sliceによる非破壊的な処理
4. イミュータブルなデータ構造の利点
イミュータブル(immutable)なデータ構造は、一度作成されるとその状態を変更することができないデータ構造のことを指す。
そのため、データの更新を行うためには新しいデータ構造を作成する必要がある。以下に、イミュータブルなデータ構造の主な利点を挙げる。
1)予測可能性と理解しやすさ: データが変化しないため、予期しない副作用が発生する可能性が低くなる。
これにより、コードの振る舞いを予測しやすくなり、デバッグも容易になる。
2)データ変更の履歴管理: イミュータブルなデータ構造では、データの変更が新しいデータ構造の作成として表現されるため、
過去の状態を保持することが容易だ。これは、例えば、ユーザーの操作を元に戻す(Undo)機能を実装する際に有用である。
3)並行性とマルチスレッドの安全性: 同時に複数の処理(スレッド)が同じデータを参照しても、データが変更されることがないため、
データ競合やデータ破壊の心配がない。
4)高階関数との親和性: プログラムの状態を変更せずに計算を行う関数型プログラミングでは、イミュータブルなデータ構造が基本となっている。
これにより、高階関数(他の関数を引数として受け取ったり、結果として関数を返す関数)との相性が良くなる。
5)純粋関数の作成: 入力が同じであれば、出力も必ず同じになる純粋な(Pure)関数を作るためには、関数内でデータを変更することができない。
つまりイミュータブルなデータ構造が必要だ。純粋な関数はテストや再利用が容易で、バグを生じにくいという特性がある。
このように、イミュータブルなデータ構造は、コードの安全性、可読性、保守性を高めるために重要な要素となる。
特に、大規模なアプリケーションやシステムにおいて、データの管理が複雑になりがちです。
そうした中でイミュータブルなデータ構造を使うことで、データの状態を一貫して保つことが可能となり、複雑さを抑えることができる。
また、リアクティブプログラミングや関数型プログラミングなど、近年のプログラミングのトレンドにも適応することができる。
例えば、JavaScriptのライブラリであるReactやReduxでは、イミュータブルなデータ構造の採用が推奨されている。
さらに、イミュータブルなデータ構造は、データの変更が起きたときにその変更を追跡しやすいという特性も持っている。
これは、パフォーマンス最適化に役立つ。例えば、Reactでは、イミュータブルなデータを使用することで、
コンポーネントの再レンダリングが必要かどうかを効率的に判断することができる。
ただし、イミュータブルなデータ構造を使うことで生じるオーバーヘッドも考慮する必要がある。
常に新しいデータ構造を生成するため、メモリ使用量が増える可能性がある。
また、新しいデータ構造を生成するコストも無視できない。これらのトレードオフを理解した上で、適切にイミュータブルなデータ構造を活用することが重要である。
5. まとめ
今回は今まで扱った配列操作の関数における、破壊的操作、非破壊的な操作について説明した。 破壊的な関数に関しては、sliceメソッドなどを上手く組み合わせることによって、非破壊的な操作にすることができる。 理由がない限りは、基本副作用のない非破壊的な操作で配列を処理した方が良い。 少し難しい内容かもしれないが、この部分だけでも覚えておこう。
▼参考図書、サイト
JavaSciptの配列操作を非破壊的に行う 十文字情報技術研究所
JavaScriptでイミュータブルに配列を操作するメソッドまとめ noah.plus