Introduction to Django for Beginners
■Episode 16: How to Use Pandas and Basic Concepts
(Last updated: 2023.06.14)
Image of Django framework
This article takes 4 minutes to read!
(Rotate your phone for a larger image)
"Let's freely manipulate data using Pandas!"
Pandas is a data analysis library used in Python programming. It provides high-level data structures and tools to make data manipulation and analysis easier. It is one of the major reasons why Python has become widely used in scientific computing and is an essential tool for data analysis and modeling.
[Table of Contents]
Features and Advantages of Pandas
How to Install Pandas
Basic Data Structures in Pandas
Summary
1. Features and Advantages of Pandas
Pandas mainly offers two data structures: Series and DataFrame. These allow for efficient handling of large datasets and support operations such as slicing and indexing. It can also handle incomplete data with ease.
For data manipulation, Pandas makes common tasks like cleaning, transformation, and aggregation straightforward. It also supports statistical data analysis, allowing for easy calculation of metrics such as mean, median, and standard deviation.
In this section, you will learn the overview of Pandas, how to install it, and understand its data structures.
2. How to Install Pandas
Since Pandas is a Python library, Python must be installed first (Python 3.7 or higher is recommended). Use pip to install it, as we did with NumPy.
For setting up a virtual environment (venv), refer to the explanation in the previous article on NumPy.
After setting up the environment, enter the command `pip install pandas` to install. If you’re using a very new version of Python, Pandas might not be compatible. In that case, try installing an earlier Python version.
If you can write `import pandas as pd` without getting an error, the installation was successful. You are now ready to use Pandas.
3. Basic Data Structures in Pandas
This section explains Pandas' main data structures: Series and DataFrame.
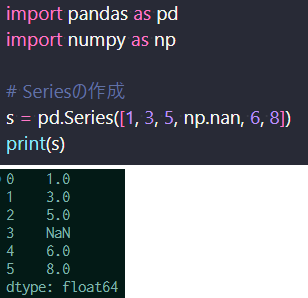
First, the Series is a one-dimensional array that holds values of the same data type (e.g., integers, strings, floats). Series are labeled with indexes, making data access and manipulation easier. Below is an example of creating a Series. You can see how it generates a labeled one-dimensional dataset.
Creating a Series
Creating a Series (Top: Code, Bottom: Output)
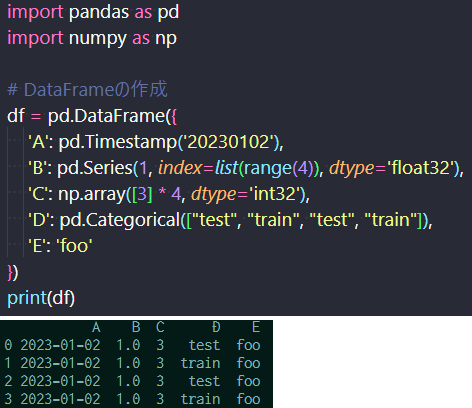
Next, the DataFrame is a two-dimensional array in Pandas that can store different types of data (e.g., numbers, strings, booleans). It uses row and column indexes for labeling, making it easy to access and manipulate data. Below is an example of creating a DataFrame. The row labels use letters, and the column labels use numbers, resembling Excel. You can see features like specifying data types (e.g., float32), inserting via arrays, and interpolation of data to fill in missing values. These features highlight the power of Pandas.
Creating a DataFrame
Creating a DataFrame (Top: Code, Bottom: Output)
4. Summary
In this article, we covered how to install Pandas and introduced its key data structures: Series and DataFrame. You’ve learned that you can mix different types of data and perform interpolation.
Unlike NumPy, Pandas allows you to label and manipulate data easily. In the next article, we will dive deeper into Pandas' features and capabilities using these data structures.
▼References
In-Depth Guide to Pandas Series by AI-inter (Python 3 tutorial)
Structure and Creation of pandas.DataFrame by note.nkmk.me