初心者のためのDjango入門
■第18話:Pandasのデータ操作とデータ変換
(最終更新日:2023.06.19)

(絵が小さい場合はスマホを横に)
「Pandasを用いてデータを自在に操ろう!」
Pandasは表計算ソフトと同じ形式でデータを保持できるため、データ操作も得意である。
今回は、ソートやマージ、フィルタリング、グループ化といった良くある操作に加えて、
欠損データに対する処理についても説明していく。
1.データの選択とフィルタリング
本項では、PandasのDataFrameから特定のデータを選択したり、 特定の条件に基づいてデータをフィルタリングする方法を説明する。 DataFrameから特定の列を選択するには、選択したい列の名前を指定する。 下記では、Name列を選択し抽出している。
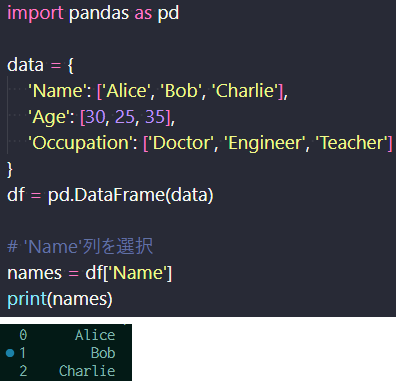
指定した列の選択
複数行を選択するには「df['Name', 'Age']」のように、カンマで区切って2つ指定することで簡単に実現できる。 また、特定の行番目を選択する、列番目を選択するには以下のように書く。

指定した順番の列と行の選択方法
最後にフィルタリングの方法を説明する。 比較演算子を用いて、特定の条件を満たす行を選択するには以下のように記述する。 下記では、「30歳以上の人」「30歳以上で医者の人」をフィルタリングしている。 複数条件は&&等の論理演算子を使って記述することができる。
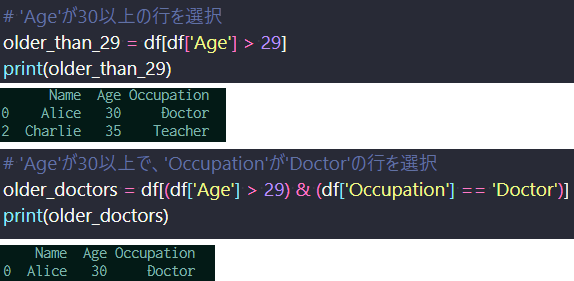
Pandasのフィルタリング
2.データの操作と変換
本項では、PandasのDataFrameを用いて、データのソート、結合、マージ、グループ化について説明する。 ソートは、df.sort_values(ソートしたい項目)とするだけで、その項目順に並べ替えられる。 下記はAge順に並べた例である。
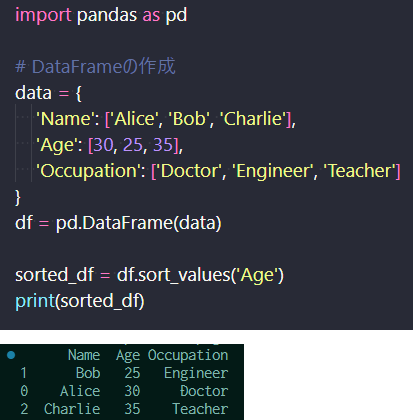
ソートの作成(上)、出力結果(下)
また、ascending=Falseと指定することで、降順(年齢の高い順)に変えることもできる。

ソートの降順(上)、出力結果(下)
2つのDataFrameを結合する場合は、concatを用いる。先ほどのdfと新たに作成したdf2を結合して、 新たにMikeの情報を追加している。
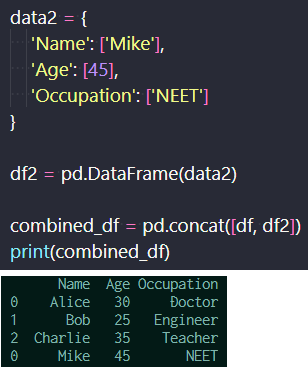
DataFrameの結合(上)、出力結果(下)
また、新たな項目追加するにはmergeを用いる。マージは、ただ追加するだけではなく、重複している項目を省く。 下記では、新たな項目として、性別を追加している。ここではNameがユニークなので、Nameに基づいてマージしている。 (ただし、同じ名前も有りうるため、通常はid番号などを用いる。)
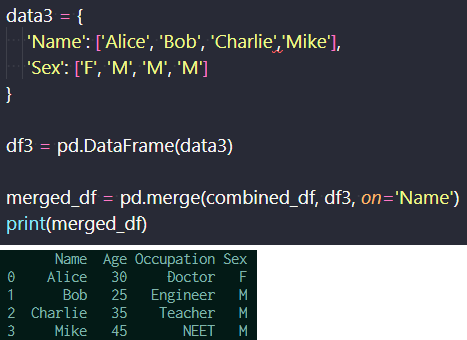
特定の列に基づくマージ(上)、出力結果(下)
目的通りのデータフレームが作成できたら、その後はデータ分析をしたいはずだ。 例えば、平均値、合計値、最大値、最小値などを算出したい。そのとき用いるのが、groupby関数になる。 以下のように用いることで、職業ごと(同一項目ごと)の平均値を簡単に算出することができる。
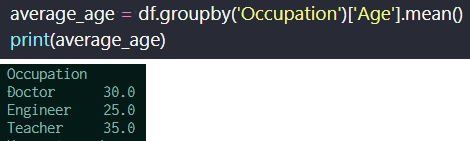
データフレームの平均値の算出(上)と結果(下)
3.欠損データの処理
Pandasを使用して欠損データ(NaNやNoneなど)を検出し、削除または補完する方法を説明する。 DataFrame内の欠損データを検出するには、isnaまたはisnull関数を使用します。 下記では、any().any()が無くても、全てのデータフレームに対して欠損値確認を行ってくれるが、全データに対して表形式でTrue, Falseを返すので見にくい。 存在するかどうかを見るには、any().any()を始めに用いることで、まず欠損が存在するのかを確認する。下記の場合は2つ欠損値があるのでTrueが返る。

欠損値があることを確認したら、そのデータに対して削除、補間、いずれかで対処する必要がある。
DeepLearningを始め、機械学習用のデータ前処理には必要なことである。
データに余裕がある時は、削除を行う。
欠損値データ行を削除するには、dropna関数を使用する。下記の通りである。
欠損値のある行が削除され、全て揃ってるデータ行だけになる。

データに余裕がない時は平均値などで補間して用いる。 欠損値データ行を削除するには、fillna関数を使用する。下記の通りである。 補間値は平均に限らず、そこで最もらしい値を使う。
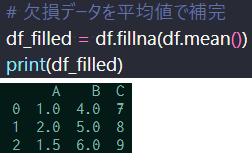
4.まとめ
今回、Pandasのデータのソート、結合、マージ、グループ化、欠損データの処理を行った。 どれも基本的で重要な操作だが、欠損データの処理はやや実践的だろう。 機械学習用のデータで、データが欠損していることはしばしばある。 どのような値を用いるか妥当性を考えた上で、値を補間していこう。
▼参考図書、サイト
Pandas loc と ilocの違いとは? AI Academy Media
Pandas の groupby の使い方 Qiita
pandasで欠損値NaNを置換(穴埋め)するfillna note.nkmk.me